
s = """Gur Mra bs Clguba, ol Gvz Crgref
Ornhgvshy vf orggre guna htyl.
Rkcyvpvg vf orggre guna vzcyvpvg.
Fvzcyr vf orggre guna pbzcyrk.
Pbzcyrk vf orggre guna pbzcyvpngrq.
Syng vf orggre guna arfgrq.
Fcnefr vf orggre guna qrafr.
Ernqnovyvgl pbhagf.
Fcrpvny pnfrf nera'g fcrpvny rabhtu gb oernx gur ehyrf.
Nygubhtu cenpgvpnyvgl orngf chevgl.
Reebef fubhyq arire cnff fvyragyl.
Hayrff rkcyvpvgyl fvyraprq.
Va gur snpr bs nzovthvgl, ershfr gur grzcgngvba gb thrff.
Gurer fubhyq or bar-- naq cersrenoyl bayl bar --boivbhf jnl gb qb vg.
Nygubhtu gung jnl znl abg or boivbhf ng svefg hayrff lbh'er Qhgpu.
Abj vf orggre guna arire.
Nygubhtu arire vf bsgra orggre guna *evtug* abj.
Vs gur vzcyrzragngvba vf uneq gb rkcynva, vg'f n onq vqrn.
Vs gur vzcyrzragngvba vf rnfl gb rkcynva, vg znl or n tbbq vqrn.
Anzrfcnprf ner bar ubaxvat terng vqrn -- yrg'f qb zber bs gubfr!"""
d = {}
for c in (65, 97):
for i in range(26):
d[chr(i+c)] = chr((i+13) % 26 + c)
print("".join([d.get(c, c) for c in s]))
上面的代码其实是一段加密的字符串进行解析,这种加密方式称为映射加密或恺撒加密,在python之禅里使用的是ASCll编码进行映射加密的
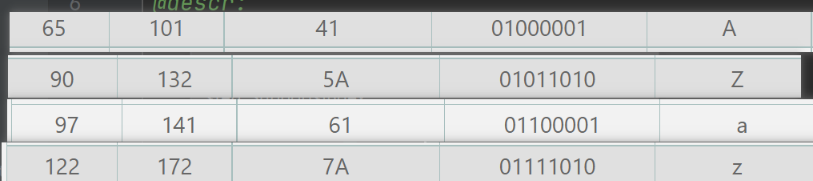

加密方式可以自定义,但是必须一一对应,如果a:a那就没有意义了,也不可能手动编写加密方式,通常是通过某种算法或者某种规律进行字符映射表的生成
手动更改的映射表
d={'A': 'O', 'B': 'N', 'C': 'P', 'D': 'Q', 'E': 'R', 'F': 'S', 'G': 'T', 'H': 'U', 'I': 'V', 'J': 'W', 'K': 'X', 'L': 'Y', 'M': 'Z', 'N': 'B', 'O': 'A', 'P': 'C', 'Q': 'D', 'R': 'E', 'S': 'F', 'T': 'G', 'U': 'H', 'V': 'I', 'W': 'J', 'X': 'K', 'Y': 'L', 'Z': 'M', 'a': 'o', 'b': 'n', 'c': 'p', 'd': 'q', 'e': 'r', 'f': 's', 'g': 't', 'h': 'u', 'i': 'v', 'j': 'w', 'k': 'x', 'l': 'y', 'm': 'z', 'o': 'a', 'n': 'b', 'p': 'c', 'q': 'd', 'r': 'e', 's': 'f', 't': 'g', 'u': 'h', 'v': 'i', 'w': 'j', 'x': 'k', 'y': 'l', 'z': 'm'}
其中加13是因为26个字母只有分13个才能组成对称映射
%26是因为有26个字母,%是取余余数就是来判断第几个母,只要使用字母表来做恺撒加密取余数必须且固定是26,偏移量是可变的,偏移量13比较特殊,偏移量为13时生成的映射表同时可以为字符串解密和加密
代码前部的字符串像是一堆乱码,但是从格式上看和Python之禅是一样的。要理解Python之禅是怎样被输出的还是要看下面的代码。
我们首先看两个嵌套的for循环,通过代码不难理解实际上通过这个循环定义了一个字典,这个字典有52个key value。这其实就是将a-z A-Z大小写两套英文字母重新做了对应。具体是怎样对应的就要去看chr()函数了。chr()函数提供了数字和ascii字符对应的功能。在段代码里看似混乱的字符串被重新做了对应,它的对应关系就保存在了d这个字典里。
接下来就是输出的环节了,join后面是一个列表推导式,它会逐个读取每个字符然后找到字典里保存的对应关系。这里用到了get()函数,它的作用是找到字典中key对应的value,第二个参数指定了如果找不到对应的值返回的默认值是什么。之前提到d字典保存了英文大小写总共52个字符的对应值,但是这里面标点符号空格换行符之类的值是没有保存对应关系的,所以在没有找到的情况下会把输入的值原样返回。最后需要join函数吧整个列表拼接成一个字符串,不然打印出来东西就会像是这个样子了:
["T", "h", "e", " ", "Z", "e", "n", " ", "o", "f", " ", "P", "y", "t", "h", "o", "n", ",", " ", "b", "y", " ", "T", "i", "m", " ", "P", "e", "t", "e", "r", "s", " ", " ", "B", "e", "a", "u", "t", "i", "f", "u", "l", " ", "i", "s", " ", "b", "e", "t", "t", "e", "r", ".....
通过上面的分析我们可以看到这个非常简单的功能并没有用定义一个字符串然后打印的简单方式实现。它的实现利用了chr()函数,get()函数,join()函数,还涉及了列表推导式,是一个非常有内容的实现。
若果要对进行加密的字符串进行解密则要知道,它对应的映射表得字母偏移量,除了13位偏移量除外(13偏移量比较特殊因为13刚好是26哥字母表的一半,不用再进行反转即可对加密的字符串进行解密)如果得到加密字符串且不是13位偏移量(不是一一对应)就要对加密的映射表进行反转

#加密后的字符串
pt='''
Ftq Lqz ar Bkftaz, nk Fuy Bqfqde
Nqmgfurgx ue nqffqd ftmz gsxk.
Qjbxuouf ue nqffqd ftmz uybxuouf.
Euybxq ue nqffqd ftmz oaybxqj.
Oaybxqj ue nqffqd ftmz oaybxuomfqp.
Rxmf ue nqffqd ftmz zqefqp.
Ebmdeq ue nqffqd ftmz pqzeq.
Dqmpmnuxufk oagzfe.
Ebqoumx omeqe mdqz'f ebqoumx qzagst fa ndqmw ftq dgxqe.
Mxftagst bdmofuomxufk nqmfe bgdufk.
Qddade etagxp zqhqd bmee euxqzfxk.
Gzxqee qjbxuoufxk euxqzoqp.
Uz ftq rmoq ar mynusgufk, dqrgeq ftq fqybfmfuaz fa sgqee.
Ftqdq etagxp nq azq-- mzp bdqrqdmnxk azxk azq --anhuage imk fa pa uf.
Mxftagst ftmf imk ymk zaf nq anhuage mf rudef gzxqee kag'dq Pgfot.
Zai ue nqffqd ftmz zqhqd.
Mxftagst zqhqd ue arfqz nqffqd ftmz *dustf* zai.
Ur ftq uybxqyqzfmfuaz ue tmdp fa qjbxmuz, uf'e m nmp upqm.
Ur ftq uybxqyqzfmfuaz ue qmek fa qjbxmuz, uf ymk nq m saap upqm.
Zmyqebmoqe mdq azq tazwuzs sdqmf upqm -- xqf'e pa yadq ar ftaeq!
'''
#解密后的字符串
st='''The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!'''
d={}
for c in (65, 97):#ascll表的字母A从65开始字母a从97开始,注意这里是65和97不是65——97,只取65和97两个数字
for i in range(26):#97+25恰好等于122是字母z
d[chr(i+c)] = chr((i+12) % 26 + c)
e={'A': 'M', 'B': 'N', 'C': 'O', 'D': 'P', 'E': 'Q', 'F': 'R', 'G': 'S', 'H': 'T', 'I': 'U', 'J': 'V', 'K': 'W', 'L': 'X', 'M': 'Y', 'N': 'Z', 'O': 'A', 'P': 'B', 'Q': 'C', 'R': 'D', 'S': 'E', 'T': 'F', 'U': 'G', 'V': 'H', 'W': 'I', 'X': 'J', 'Y': 'K', 'Z': 'L', 'a': 'm', 'b': 'n', 'c': 'o', 'd': 'p', 'e': 'q', 'f': 'r', 'g': 's', 'h': 't', 'i': 'u', 'j': 'v', 'k': 'w', 'l': 'x', 'm': 'y', 'n': 'z', 'o': 'a', 'p': 'b', 'q': 'c', 'r': 'd', 's': 'e', 't': 'f', 'u': 'g', 'v': 'h', 'w': 'i', 'x': 'j', 'y': 'k', 'z': 'l'}
print('加密映射表:',d)
# print("".join([d.get(c, c) for c in st]))#将文本字符串进行加密,如果在加密映射表里没有出现的字符则取文本字符串原始的值
new_e={key:value for value, key in e.items()}#反转加密映射表
print('解密映射表:',new_e)
print('解密后的文本',''.join([new_e.get(s,s) for s in pt]))#循环被加密的文本字符串,循环提取每个字符在解密映射表里取出对应的解密字母
#如果没有这个字符的话还使用文本字符串原始的字符,因为解密字符串是根据加密字符串生成的,只要加密字符串没对其进行操作,解密映射表也无法对字符操作所以取他原始的值
#最后需要join函数把整个列表拼接成一个字符串,不然打印出来东西就会是单独每个字符占用一个引号进行打印了,join前面是空而不是空格(两者有区别打印时作用不一样)
#以空拼接会将每个字符连接起来,且特殊字符(比如空格和换行)会保留,保持原始格式
#拼接之前['\n', 'T', 'h', 'e', ' ', 'Z', 'e', 'n', ' ', 'o', 'f', ' ', 'P', 'y', 't', 'h', 'o', 'n']
#拼接之后The Zen of Python
